
国立国会図書館ダブリンコアメタデータ記述(DC-NDL)解説
このページでは「国立国会図書館ダブリンコアメタデータ記述(DC-NDL)」について解説します。アスタリスク(*)を付記した用語は、【参考】メタデータ関連用語集にリンクしています。
1. DC-NDLの概要
国立国会図書館は、情報資源の組織化および利用提供のためのメタデータ標準として「国立国会図書館ダブリンコアメタデータ記述(DC-NDL)」を定めています。DC-NDLは、国際的なメタデータ標準であるDublin Core(ダブリンコア)*をもとに(解説:ダブリンコアについてを参照)、日本語対応など独自に拡張したメタデータ記述語彙および記述規則の総称です。
DC-NDLでは、ダブリンコアを代表とする国際的なメタデータ標準で定義された語彙に加えて、国立国会図書館のメタデータ記述で必要となる語彙を独自定義するほか、既存語彙および独自語彙の双方を用いた標準的なメタデータ記述方法について定めています。
最新版は、国立国会図書館ダブリンコアメタデータ記述(DC-NDL2020年12月版)です。DC-NDLのこれまでの変遷については、解説:DC-NDLの変遷をご参考ください。
2. DC-NDLの特徴
DC-NDLの主な特徴をアプリケーションプロファイルへの対応、既存語彙+独自語彙の併用、セマンティックウェブ志向、過去の基準の取扱いの4点に分けて説明します。
2.1. アプリケーションプロファイルへの対応
ダブリンコア*では、メタデータの相互運用性を向上するための基礎的なモデルとして、アプリケーションプロファイル*を提唱しています。アプリケーションプロファイルは、メタデータの記述にどのような語彙を使用し、その語彙を用いてどのような形式で記述するかを定義したメタデータの記述規則です。語彙のグローバルな共有を促し、相互利用性を高めるとともに、各メタデータ作成・提供機関による柔軟なメタデータ記述規則の設定を可能とするため、語彙の意味(セマンティクス)と語彙の記述方法・記述形式(シンタックス)は分けて定義することが推奨されています。アプリケーションプロファイルは後者の語彙の記述方法・記述形式を定めるものであり、前者の語彙の意味を定義する基本記述要素集合(語彙集)*とは別に作成されます。(ダブリンコアにおけるアプリケーションプロファイルについては解説:ダブリンコアについて―アプリケーションプロファイル、語彙の意味(セマンティクス)と語彙の記述方法・記述形式(シンタックス)の分離については解説:セマンティクスとシンタックスの分離も併せてご参照ください。)
アプリケーションプロファイルの方法を取り入れることにより、メタデータ作成・提供機関は、ダブリンコアのような既存語彙が利用できる場合にはそれを使用し、利用できない場合には語彙を独自定義し、既存語彙と独自語彙の双方を組み合わせてメタデータスキーマ*を構成できるようになります。従来のメタデータ記述規則では、他の規則で同じような意味を持つ語彙が定義されていた場合でも、一つの完結したシステム内でメタデータスキーマを定義するために、独自語彙として定義することが行われてきました。この方法に拠ると、異なるメタデータスキーマに基づいて作成されたメタデータを相互運用するためには、語彙ごとにマッピング(対応づけ)を定義する必要が生じます。一方、アプリケーションプロファイルの枠組みに基づき、各メタデータスキーマでダブリンコアに代表される標準的な既存語彙を採用し、語彙の共有を進めることで、語彙やメタデータスキーマ間のマッピングにかかるコストを低減させ、メタデータの相互運用性を向上させることができます。
DC-NDLでは、こうしたアプリケーションプロファイルの枠組みを取り入れ、「語彙の意味」と「語彙を用いたメタデータの記述方法・記述形式」を分けて定義しています。DC-NDLは三部のドキュメントで構成されていますが(「3. DC-NDLの構成」を参照)、第一部のNDL Metadata Termsは、国立国会図書館独自の語彙の意味を定義し、第二部のApplication Profileは、既存語彙および独自語彙の双方について、語彙に収める値の形式や入力レベルの目安といった語彙の記述方法・記述形式を定義しています。
2.2. 既存語彙+独自語彙の併用
2.1. アプリケーションプロファイルの枠組みへの対応で述べたとおり、DC-NDLでは、国立国会図書館のメタデータ記述で必要となる語彙が、ダブリンコアを代表とする主要なメタデータ標準で定義されている場合には、それを使用し、定義されていない場合には、独自定義しています。既存語彙と独自語彙の双方を含め、DC-NDLで使用する語彙は、以下のとおりです。
| 語彙名 | 名前空間名 | 接頭辞 | 説明 |
|---|---|---|---|
| DCMIメタデータ語彙(DCMI Metadata Terms) | http://purl.org/dc/terms/ | dcterms | ダブリンコアの維持管理団体であるダブリンコアメタデータイニシアチブ(DCMI)*が定める55個のプロパティ*等のメタデータ記述語彙。 詳細は、解説:ダブリンコアについて―ダブリンコアメタデータ基本記述要素集合とDCMIメタデータ語彙を参照 |
| ダブリンコアメタデータ基本記述要素集合1.1版(The Dublin Core Metadata Element Set, Version 1.1) | http://purl.org/dc/elements/1.1/ | dc | DCMIが定めるタイトル・作成者等の15ターム。いわゆるSimple DC。 詳細は、解説:ダブリンコアについて―ダブリンコアメタデータ基本記述要素集合とDCMIメタデータ語彙を参照 |
| DCMIタイプ語彙(DCMI Type Vocabulary) | http://purl.org/dc/dcmitype/ | dcmitype | DCMIが定める情報資源の種別を示すための語彙 |
| FOAF Vocabulary | http://xmlns.com/foaf/0.1/ | foaf | 人に関する情報をRDF(Resource Description Framework)*で記述するための語彙 |
| RDF Vocabulary | http://www.w3.org/1999/02/22-rdf-syntax-ns# | rdf | RDFモデル構文の名前空間で定義される語彙 |
| RDF Schema Vocabulary | http://www.w3.org/2000/01/rdf-schema# | rdfs | RDFスキーマの名前空間で定義される語彙 |
| OWL Web Ontology Language | http://www.w3.org/2002/07/owl# | owl | ウェブ・オントロジー言語による情報資源の記述に使用する語彙 |
| NDL Metadata Terms | http://ndl.go.jp/dcndl/terms/ | dcndl | DC-NDLで独自定義するプロパティ等のメタデータ記述語彙 |
| NDLタイプ語彙(NDL Type Vocabulary) | http://ndl.go.jp/ndltype/ | ndltype | DC-NDLで独自定義する情報資源の種別を示すための語彙 |
DC-NDLでは、以下の情報には、既存の語彙を用いています。リンク先でDC-NDLで使用した既存の語彙を確認できます。
- タイトル、作成者、出版者(公開者)、内容記述などの基本的な書誌情報
DCMIメタデータ語彙(DCMI Metadata Terms)、ダブリンコアメタデータ基本記述要素集合1.1版(The Dublin Core Metadata Element Set, Version 1.1) - デューイ十進分類法(DDC)、米国議会図書館件名標目表(LCSH)、ISO言語コード(ISO 639-2)等の国際的な統制語彙・コードの符号化スキーム
DCMIメタデータ語彙(DCMI Metadata Terms) - 関連するURLへの参照(See Also)
RDF Schema Vocabulary - 一次資料にアクセス可能なURI(Same As)
OWL Web Ontology Language - 資料のサムネイル画像URI(Thumbnail)
FOAF Vocabulary
一方、国立国会図書館が独自に定義する語彙には、以下のようなものがあります。
- よみ、各種タイトル、内容細目、版表示、価格等のいわゆる書誌情報
- 博士論文、デジタル化資料、雑誌記事等の資料の特性に関する語彙
- 請求記号、所蔵する逐次刊行物の巻次等の機関の所蔵情報に関する語彙
- 国立国会図書館のサービス要件(総合目録ネットワーク等)に関する語彙
独自語彙がDCMIメタデータ語彙またはダブリンコアメタデータ基本記述要素集合1.1版の語彙を精緻化・詳細化したものである場合、独自語彙をこれら既存語彙の下位プロパティまたは下位クラスとして定義します。例えば、シリーズタイトル(dcndl:seriesTitle)は、ダブリンコアのタイトル(dc:title)の下位プロパティとして定義しています。このように語彙間の関係性を定義することにより、後述のセマンティックウェブ*に対応したプログラム(エージェント)が、関係性を用いた推論や自動処理を行うことが可能になります。
2.3. セマンティックウェブ志向
DC-NDLは、ウェブ上の情報資源に意味の明確なデータを付与し、機械的な意味処理を目指すセマンティックウェブ*への対応を行っています。
DC-NDLでは、セマンティックウェブにおけるメタデータの標準的な表現方法であるRDF (Resource Description Framework)*による記述が可能となるように語彙定義を行っています。例えば、RDFの構造化表現(解説:構造化表現の必要性を参照)を用いて、タイトルとその読みをセットで表現できるように、読みを記述するための語彙dcndl:transcriptionを設定しています。一方、DC-NDLを採用するシステムや機関が必ずしもRDFに対応できるとは限らないため、RDF形式で記述できない場合の語彙もDC-NDLでは用意しています。例えば、タイトルをRDFの構造化表現により読みと値をセットで表現できない場合は、読みをdcndl:titleTranscriptionで表現することができます(解説:Transcriptionと○○Transcriptionの使い分けを参照)。
DC-NDLでは、独自定義した語彙の意味を機械にも理解可能にするために、語彙の記述対象となるリソースの範囲を指定する定義域、語彙の値が取り得る範囲を指定する値域をそれぞれ設定するとともに、DCMIが定義する主要な語彙と下位プロパティの関係を設定し、これらの内容をRDFスキーマ*として定義しています。
DC-NDLでは、名前空間ごとに、NDL Metadata Terms(RDF: 90KB)、NDLタイプ語彙(RDF: 35KB)のRDFスキーマを用意しています。
2.4 過去の基準の取扱い
DC-NDLは過去に改訂を行っており(解説:DC-NDLの変遷を参照)、版の区別には年月次を使用しています。
- 「DC-NDL2007年版」
- 「DC-NDL2010年6月版」
- 「DC-NDL2011年12月版」
- 「DC-NDL2020年12月版」(最新版)
旧版を採用しているシステムもあるため、改訂後も過去の標準を引き続き公開しています。
3. DC-NDLの構成
DC-NDLは第一部 NDL Metadata Terms、第二部 Application Profile、第三部 RDFスキーマの三部構成です。ここでは、各部の概要および全体構成についてご説明します。
3.1. 第一部 NDL Metadata Terms
第一部 NDL Metadata Terms(PDF: 1.3MB)は、国立国会図書館が独自に定義したメタデータの記述のための語彙集です。読み(dcndl:transcription)、シリーズタイトル(dcndl:seriesTitle)、博士論文の学位名(dcndl:degreeName)などを定義しています。各語彙で定義する項目は、以下のとおりです。
| 項目 | 内容 | dcndl:transcriptionの例 |
|---|---|---|
| 語彙の名前 | Transcription | |
| URI | 当該語彙が意味定義されているURI* | http://ndl.go.jp/dcndl/terms/transcription |
| 表示名 | 利用者の理解を助けるために与える短い表示名 | Transcription |
| 定義 | NDL Metadata Termsで与える語彙の定義 | 読み又は翻字形 |
| 補足説明 | 「定義」の詳細・補足説明等 | Title、Creator等の値とセットで表現できる場合に使用する。 |
| 語彙のタイプ | 語彙のタイプ。プロパティ*、語彙符号化スキーム*、構文符号化スキーム*、クラス*のいずれかを選択する。 | プロパティ |
| 上位プロパティ | 当該語彙の上位にあるプロパティ | ― |
| 「をも見よ」参照 | 関係のある語彙の参照先 | ― |
| 定義域 | プロパティの主語が取りうるクラスの範囲 | ― |
| 値域 | プロパティの値が取りうるクラスの範囲 | http://www.w3.org/2000/01/rdf-schema#Literal |
| ~のサブクラスである | 当該語彙が属する上位のクラス | ― |
| ~のメンバーである | 当該語彙が属する語彙符号化スキームのセット | ― |
| 語彙の作成日 | NDL Metadata Termsで当該語彙を定義した年月日 | 2010-06-21 |
| 語彙の最終更新日 | NDL Metadata Termsで当該語彙を最後に更新した年月日 | 2011-12-01 |
DCMIが定義する語彙、例えばタイトル(dcterms:title)、作成者(dcterms:creator)等については、DC-NDLでは再定義していないため、第一部には含まれていません。DCMIが定義する語彙を含むDC-NDLで採用する全語彙の一覧については、付録 語彙一覧表(PDF: 296KB)をご参照ください。
3.2. 第二部 Application Profile
第二部 Application Profile(PDF: 1.55MB)は、DCMI等が定義する語彙、国立国会図書館が独自定義する語彙の双方を用いたメタデータの標準的な記述方法を説明したものです。以下のとおり、各語彙の使用法、表現例、値の記述形式、入力レベル等を定めています。
| 項目 | 内容 | dcndl:transcriptionの例 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 語彙の名前 [QName] |
Transcription [dcndl:transcription] | |||||||||
| プロパティURI (Property URI) |
当該プロパティを表す、参照先となるURIを示す。 | http://ndl.go.jp/dcndl/terms/transcription | ||||||||
| QName (Qualified Name for Property) |
接頭辞と語彙の組み合わせによって、プロパティURIの短縮形を表す。 | dcndl:transcription | ||||||||
| 定義の発生源 (Defined by) |
プロパティの定義元をURIで示す。 | NDL Metadata Terms http://ndl.go.jp/dcndl/terms |
||||||||
| 語彙のタイプ (Type of Term) |
語彙のタイプを記す。 | プロパティ | ||||||||
| 表示名 (Label) |
利用者の理解を助けるために与える短い表示名(Label)。利用の場面において、この表示名の採用を求めるものではない。 Application Profileでは、当該語彙(Property)がNDL Metadata Termsで独自に定義したものでなければ、原則として定義元によって与えられたLabelをそのまま採用する。 |
Transcription | ||||||||
| 使用法 (Usage in Application Profile) |
Application Profileにおける使用法を記す。元の定義については、DCMIメタデータ語彙(DCMI Metadata Terms)、及びNDLMetadata Termsをそれぞれ参照のこと。 | 当該情報資源の読み又は翻字形をここに収める。 | ||||||||
| 補足説明 (Comment for Usage in Application Profile) |
「使用法」の詳細・補足説明等を記す。 | DC Title、DCTERMS Creator等の値とセットで表現する。ある一つの値に対し、読みが複数ある場合はTranscriptionを繰り返す。 | ||||||||
| 語彙符号化スキームの使用 (Uses Vocabulary Encoding Scheme) |
当該語彙に使用する語彙符号化スキーム(Vocabulary Encoding Scheme)*を示す。 語彙符号化スキームは、必要に応じて使用する。各語彙における語彙符号化スキームの採否、出現順序、繰返しについては、Application Profileでは制約を設けない。 |
指定しない | ||||||||
| 値(Value)の記述形式 | プロパティ(Property)の値(Value)の記述形式を示す。URI(Value URI)による記述、任意の文字列(Value String)による記述、構文符号化スキーム(Syntax Encoding Scheme)*による記述、入れ子による記述(Rich Representation)がそれぞれ可能であるかどうか記す。 入れ子による記述とは、RDF形式を用い、構造化して表現することを指す。 また、記述形式に制約がある場合はここに示す。 |
|
||||||||
| 表現例 (RDF/XML) |
RDF/XML形式による表現例を示す。「△」は半角スペースを意味する。 |
|
||||||||
| 入力レベル (Obligation) |
DC-NDLにおける記述の入力レベルの目安を、「必須」、「あれば必須」、「推奨」、「選択」の4段階で示す。 | 推奨 |
「第二部 Application Profile」で規定するメタデータの記述方法は、特定のシステムの実装に基づかない、国立国会図書館における標準的な記述方法を示したものであり、入力レベルの目安を示しているものの、各語彙の採否については各システムで定めることとしています。また、出現順序、繰り返し(最大出現回数・最小出現回数)についても各システムにおいて個別に定義することとし、原則として制約を設けていません。そのため、各システムでは、「第二部 Application Profile」を基に、各自のサービス要件・システム要件を踏まえて、別途アプリケーションプロファイルを用意する必要があります。
3.3. 第三部 RDFスキーマ
第三部 RDFスキーマは、国立国会図書館で独自定義した語彙「NDL Metadata Terms」をRDF形式で記述したファイルです。RDF形式で語彙定義を行うことにより、その語彙がどのような意味を持つのか、どの語彙と上下関係にあるのか、どのリソースを記述対象とし(定義域)、どの範囲の値を記述できるのか(値域)といった語彙定義の内容をコンピュータが理解できるようになります。
NDL Metadata Terms(プロパティ・語彙符号化スキーム・構文符号化スキーム)(RDF: 90KB)のファイルから、読みの表現に使用する語彙「Transcription」の定義部分を抜粋すると以下のとおりです。
<rdf:Description rdf:about="http://ndl.go.jp/dcndl/terms/transcription">
<rdfs:label>Transcription</rdfs:label>
<rdfs:comment>読み又は翻字形</rdfs:comment>
<dcterms:description>Title、Creator等の値とセットで表現できる場合に使用する。</dcterms:description>
<rdf:type rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
<rdfs:range rdf:resource="http://www.w3.org/2000/01/rdf-schema#Literal"/>
<dcterms:created>2010-06-21</dcterms:created>
<dcterms:modified>2011-12-01</dcterms:modified>
</rdf:Description>
冒頭の2行で「http://ndl.go.jp/dcndl/terms/transcription」のURIで定義された語彙名「Transcription」についての記述であることが述べられます。3行目のrdfs:commentで語彙の定義、4行目のdcterms:descriptionで補足説明、5行目のrdf:typeでこの語彙がプロパティであることを示し、6行目のrdfs:rangeでこの語彙の値域が文字列(リテラル)に制約されることを示しています。7行目のdcterms:created、8行目のdcterms:modifiedはそれぞれ語彙の作成日と更新日を表しています。
3.4. DC-NDLの全体構成について(1): 概念モデル
DC-NDLでは、「管理情報」、「書誌情報」、「個体情報」の三層構造とし、各データ間をリンクするデータモデルをとっています。「管理情報」はメタデータ自体に関する管理情報、「書誌情報」は記述対象リソースの書誌情報、「個体情報」は各図書館等の所蔵情報をそれぞれ表現します。
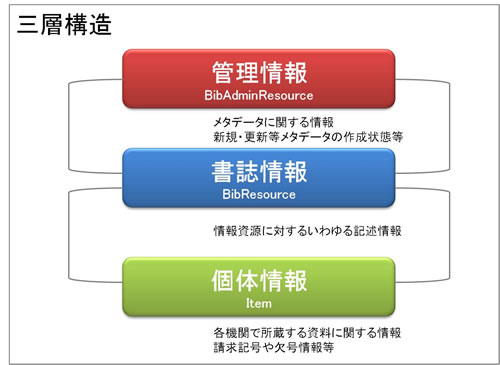
図1:概念モデルのイメージ図
3.5. DC-NDLの全体構成について(2): 語彙の分類
DC-NDLで使用する語彙は、「プロパティ」「語彙符号化スキーム」「構文符号化スキーム」「クラス」「NDLタイプ語彙」の5つに分類されます。「プロパティ」は更に「標準的なプロパティ」と「拡張的なプロパティ」に細分されます。
- プロパティ:リソースの属性を記述するのに使用。
- 標準的なプロパティ
- 図書や雑誌記事等の一般の書誌情報の記録に使用される語彙(Title、Creator、Series Title、Edition等)
- RDF形式による記述に適した語彙(Transcription等)
- 拡張的なプロパティ
- システム上の制約等によりRDF形式に対応できない場合の語彙(Title Transcription、Creator Transcription等)
- 国立国会図書館のサービス要件上、必要な語彙(Bibliographic Record Category、Cataloguing Status等)
- 標準的なプロパティ
- 語彙符号化スキーム: プロパティのとる値がどのような統制語彙(分類表、シソーラス等)に基づくかを示すのに使用。語彙符号化スキームには、NDC(日本十進分類法)、NDLC(国立国会図書館分類表)、NDLSH(国立国会図書館件名標目表)、NDLGFT(国立国会図書館ジャンル・形式用語表)等があります。
- 構文符号化スキーム: プロパティのとる値がどのような構文(形式・書式)で記述されているかを示すのに使用。構文符号化スキームには、ISBN(国際標準図書番号)、ISSN(国際標準逐次刊行物番号)、ISO 639-2(言語コード)等があります。
- クラス: リソースをグループ化するためのカテゴリーを示すのに使用。DC-NDLでは、クラスとして、Bib Admin Resource(管理情報のクラス)、Bib Resource(書誌情報のクラス)、Item(個体情報のクラス)を定義しています。これは上述した三層構造の表現に使用しています。
- NDLタイプ語彙: 記述対象リソースの種類を表現するのに使用。形態的な種別(Book, Article, Newspaper, National Publication)や内容的な種別(Painting, Music)を定義しています。
4. DC-NDLのメタデータフォーマット(エンコーディング方式)
システムのメタデータスキーマ*にDC-NDLを採用する場合、各システムの内部では、それぞれに適したデータ形式で実装しても問題ありませんが、メタデータをシステム間で交換・共有する場合、相互運用性を確保するために、標準的なメタデータフォーマット(エンコーディング方式)で入出力を行うことが望まれます。そのため、国立国会図書館ではRDF/XML形式による「DC-NDL(RDF)」というメタデータフォーマットを用意しています。
このメタデータフォーマットは、国立国会図書館における標準的なメタデータ語彙の記述方法を示した第二部 Application Profileをもとに、実際のシステムにおけるメタデータの入出力に対応するように最大出現回数・最小出現回数や入力レベル等を具体的に設定しています。詳細は、DC-NDL(RDF)フォーマット仕様(国立国会図書館サーチ)をご覧ください。
5. DC-NDLはつながる ~おわりに~
国立国会図書館は、保有するメタデータをウェブと親和性の高い機械可読形式で提供し、様々なシステムやアプリケーションでの利活用が可能になるように、語彙の定義やメタデータフォーマット仕様の整備を進めてきました。近年、機械可読形式で構造化データをウェブ上に公開し、連係させることによって、構造化データ同士がリンクし合う「データのウェブ(Web of Data)」と呼ばれるグローバルな情報空間を形成する仕組みとしてLinked Data*が注目を集めています。図書館界においてもLinked Dataの実践が進んでおり、2011年10月にはW3Cの図書館Linked DataインキュベータグループがLinked Dataを図書館データに適用することの利点やその方法等を提言する最終報告書を刊行しました(日本語訳)。DC-NDLは、このLinked Dataの世界に図書館データを接続するための役割を果たすことを目指しています。
国立国会図書館が作成し、維持管理する書誌データは国立国会図書館サーチから、典拠データは国立国会図書館典拠データ検索・提供サービス(Web NDL Authorities)からそれぞれLinked Dataに対応した形式でメタデータの提供を行っています。これらのシステムで提供されるメタデータのデータモデル図は以下のとおりです。
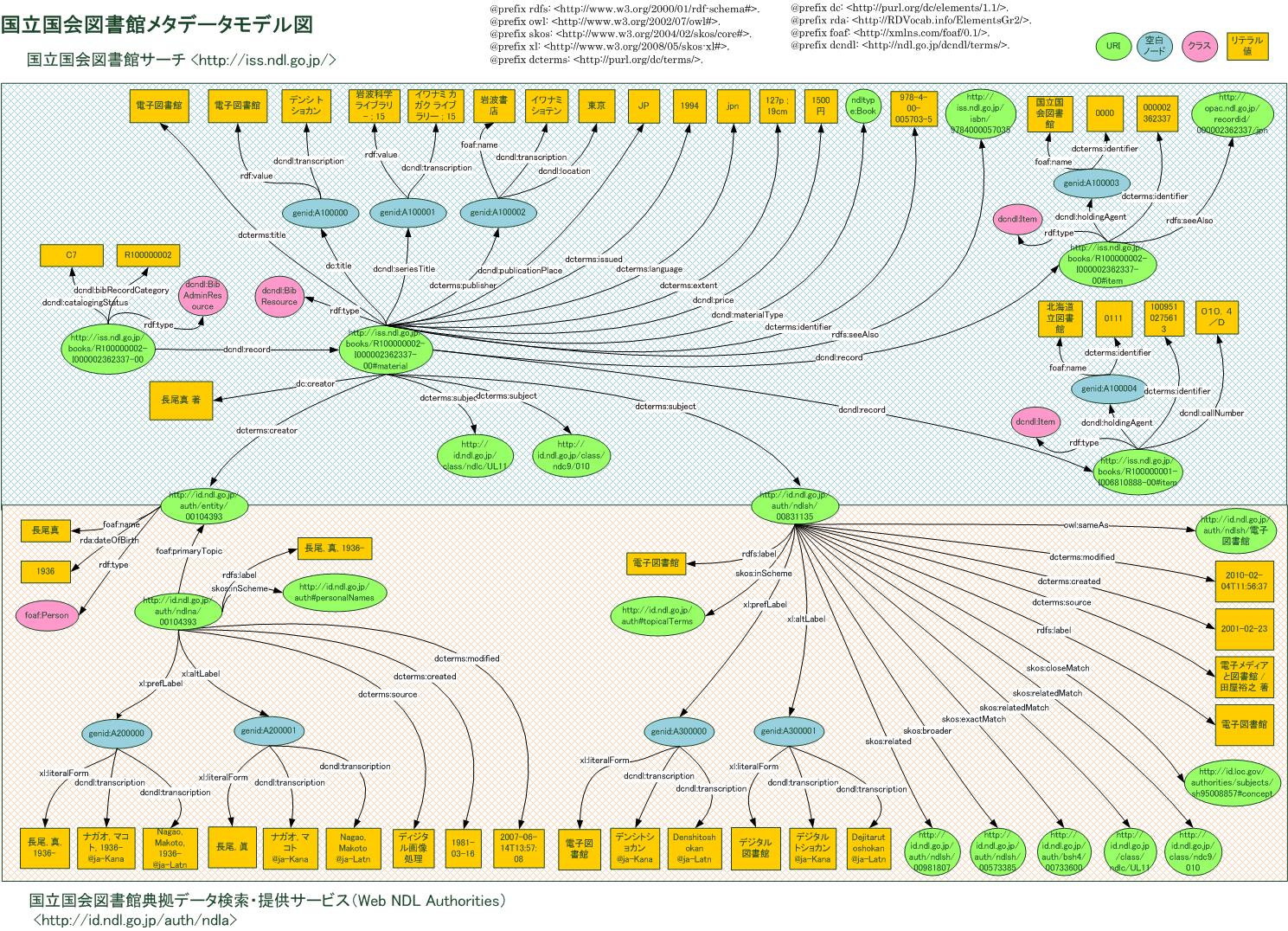
※クリックすると拡大表示します。
図5:国立国会図書館メタデータモデル図
書誌データの著者標目からは著者実体URI*、件名標目からは件名典拠URIにそれぞれリンクし、これらのURIに対して標目形・参照形・根拠・注記等の典拠情報が記述されます。典拠データ中にリンク情報がある場合は、ヴァーチャル国際典拠ファイル(VIAF)や米国議会図書館件名標目表(LCSH)にリンクしており、国際的な「データのウェブ」の世界へと繋がっています。このようにDC-NDLは、図書館データを機械可読形式による構造化データとして表現可能にすることで、「データのウェブ」の世界へと橋渡しする役割を担っています。
DC-NDLは、これまで図書館が蓄積してきたデータをウェブの世界につなげるということに加え、交換用メタデータスキーマとして、各システム間を連携させる、つまりはシステム間のメタデータ交換で共通して利用される「ハブ」となることによって、メタデータの相互運用性の向上に資することも目的としています。メタデータの相互運用性を向上させ、メタデータの共有を進めることで、ユーザとコンテンツを結ぶルートをより豊かにすることも可能になります。国立国会図書館では、メタデータの円滑で効率的な交換・共有が一層進展するよう、コンピュータにも人にも理解しやすく、より汎用的で可用性の高いメタデータ標準として、DC-NDLを維持管理し、普及させていくことを目指しています。
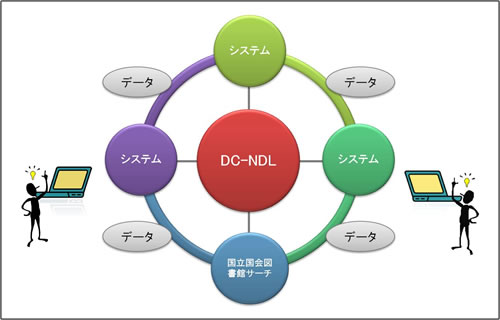
図6:DC-NDLがシステム間のメタデータ交換・共有におけるハブとなる図
解説:ダブリンコアについて
ダブリンコア*は、1995年頃からインターネット上の情報資源の発見を目的として開発が進められたメタデータ記述要素です。ダブリンコアメタデータイニシアチブ(DCMI: Dublin Core Metadata Initiative)*のもと、維持管理が行われています。
ダブリンコアメタデータ基本記述要素集合とDCMIメタデータ語彙
ダブリンコアの中核となる15タームを定義したのがダブリンコアメタデータ基本記述要素集合(DCMES: The Dublin Core Metadata Element Set)*です。このDCMESは、1997年秋に実質的に確定し、その後、2000年にCEN/ISSS(CWA 13874)、2001年10月にANSI(Z39.85)でそれぞれ標準化され、2003年には国際標準(ISO 15836)として定められました。2005年には国内標準(JIS X 0836)としても規格化されました。
DCMESは、ダブリンコアメタデータ基本記述要素集合1.1版(The Dublin Core Metadata Element Set, Version 1.1)としてDCMIのウェブサイト上で公開されています。DCMESは、Simple DCとも呼ばれています。
DCMESは、シンプルかつ自由度の高いメタデータ記述が可能であることから広く普及しましたが、セマンティックウェブ*環境でのコンピュータによる自動処理には、より厳密で精緻なメタデータ記述が必要とされる等の理由から、見直しが図られ、2008年1月にはDCMESとは別の名前空間に、15タームを含む計55個の記述要素(プロパティ)を定義したDCMIメタデータ語彙(DCMI Metadata Terms)*が新たに公開されました。
DCMIメタデータ語彙では、各プロパティに記述対象の範囲を指定する定義域*、値の範囲を指定する値域*を設定したほか、プロパティに加えて、値の属する統制語彙(分類表、シソーラス等)を指定する「語彙符号化スキーム」計9個、値の記述形式を示す「構文符号化スキーム」計12個、共通する特性を有する要素をグループ化するためのカテゴリーを示す「クラス」計22個、情報資源のタイプを示す「DCMIタイプ語彙」計12個をそれぞれ定義しています。
現在、DCMESは旧式の語彙(レガシー)として位置づけられ、DCMIメタデータ語彙の使用が推奨されています。
ダブリンコアメタデータ基本記述要素集合(DCMES: The Dublin Core Metadata Element Set)
- ダブリンコアの中核となる15タームを定義
- 国際標準(ISO 15836)、国内標準(JIS X 0836 ダブリンコアメタデータ基本記述要素集合)
- シンプルで記述の自由度が高い
- 旧式の語彙(レガシー)の位置づけ
| 基本記述要素名 | 表示名 (※JIS X 0836に準拠) |
|---|---|
| Title | タイトル |
| Creator | 作成者 |
| Subject | キーワード |
| Description | 内容記述 |
| Publisher | 公開者 |
| Contributor | 寄与者 |
| Date | 日付 |
| Type | 資源タイプ |
| Format | 記録形式 |
| Identifier | 資源識別子 |
| Source | 出処 |
| Language | 言語 |
| Relation | 関係 |
| Coverage | 時空間範囲 |
| Rights | 権利管理 |
- DCMESとは別の名前空間に、15タームを含む計55の記述要素(プロパティ)を定義
- 15タームを再定義し、DCMESの各記述要素に対する下位プロパティと位置づける
- 各プロパティに対して、定義域と値域を設定
- プロパティ以外にも、9個の語彙符号化スキーム、12個の構文符号化スキーム、22個のクラス、12個のDCMIタイプ語彙を定義
DCMI抽象モデル
ダブリンコアでは、メタデータの相互運用性を担保するための基礎的モデルとして、2000年代後半にDCMI抽象モデル(DCMI Abstract Model)*やアプリケーションプロファイル(Application Profile)*が整備されました。
DCMI 抽象モデルは、セマンティックウェブにおけるメタデータの表現方法としてW3C(World Wide Web Consortium)により規格化されているRDF(Resource Description Framework)*のモデルをもとに、ダブリンコアメタデータの概念的な構造を示したものです。DCMI抽象モデルは、2005年3月に推奨となり、その後2007 年6 月に改訂されて現在に至ります。DCMI抽象モデルでは、統一モデリング言語(UML)の記法を使用して、以下のような構造を示しています。
- メタデータレコードは、1個以上の記述セット(Description Set)から構成される。
- 記述セットは、1個以上の記述(Description)から構成される。
- 記述は、1個以上の文(Statement)、0または1個の記述対象リソースのURIから構成される。
- 文は、一つ以上のプロパティとその値の対で構成される。
- 値はリテラル(文字列で値を直接表現する:Literal Value)または非リテラル(Non-Literal Value)のいずれかをとる。
アプリケーションプロファイル
DCMI抽象モデルがダブリンコアメタデータに内在する概念的な構造モデルを示すのに対し、メタデータを実際に作成・提供する際に適用するメタデータスキーマの構成規則や符号化方法を示すのがアプリケーションプロファイル*です。例えば、アプリケーションプロファイルとして有名なものに、図書館データを対象とするDC-Library Application Profile (DC-Lib)、学術論文を対象とするScholarly Works Application Profile (SWAP)、コレクションを対象とするDublin Core Collections Application Profileがあります。これらは、それぞれの場合において、記述対象となるリソースの特徴に合わせて、どのようにメタデータスキーマを構成し、符号化するかを定めています。
アプリケーションプロファイルは、2007年8月にシンガポールで開催された「ダブリンコアとメタデータの応用に関する国際会議(DC2007)」において、シンガポールフレームワーク*と呼ばれる枠組みが示され、2008年1月にアプリケーションプロファイルのためのシンガポールフレームワーク(The Singapore Framework for Dublin Core Application Profiles)(日本語訳)として文書化されました。その後、2009年5月に、アプリケーションプロファイルの考え方を詳説したダブリンコア・アプリケーションプロファイルのためのガイドライン(Guidelines for Dublin Core Application Profiles)(日本語訳)が公開されました。
アプリケーションプロファイルの枠組みを示す「シンガポールフレームワーク」は、以下の図で示されます。
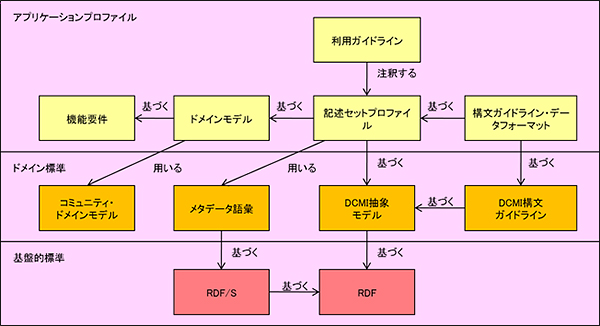
図7:シンガポールフレームワークの図(”http://dublincore.org/documents/singapore-framework/”の図を和訳)
アプリケーションプロファイルは、「機能要件」「ドメインモデル」「記述セットプロファイル」「利用ガイドライン」「構文ガイドライン・データフォーマット」から構成されます。各構成要素の説明は以下のとおりです。
- 機能要件
アプリケーションプロファイルが対象とする機能と同時にスコープ外となる機能を定義します。 - ドメインモデル
アプリケーションプロファイルで記述される基礎的な実体及びそれらの主要な関係を定義します。 - 記述セットプロファイル
アプリケーションプロファイルによって定義されるシステムやサービスにおけるメタデータレコードの構造制約を定義し、妥当性検証を可能にするための要素です。使用するメタデータ語彙やその値形式など、メタデータの記述規則を規定します。 - 利用ガイドライン
アプリケーションプロファイルの適用方法、適用時に意図されているプロパティの使用法等のガイドラインです。 - 構文ガイドライン・データフォーマット
アプリケーションプロファイルで示されるメタデータスキーマをシステムやサービスで実装するための符号化方式またはそのガイドラインです。
アプリケーションプロファイルを規定する際、この5つの要素のうち、「機能要件」「ドメインモデル」「記述セットプロファイル」の定義は必須とされており、「利用ガイドライン」「構文ガイドライン」は任意です。
図7のシンガポールフレームワークに示されるように、「メタデータ語彙」は、個々の分野・領域において合意された標準である「ドメイン標準」の領域において定義され、どの語彙をどのように使用するかは、アプリケーションプロファイルの「記述セットプロファイル」で規定することになります。下図で示すとおり、「記述セットプロファイル」では、複数の「メタデータ語彙」を選択して作成することができます。
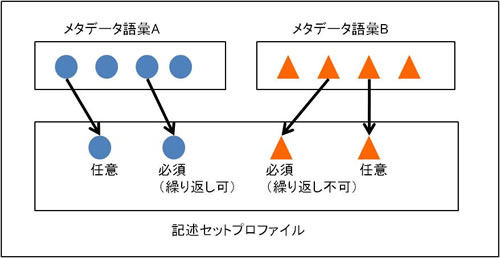
図8:メタデータ語彙と記述セットプロファイルの関係性
前述の2.1. アプリケーションプロファイルへの対応で説明するとおり、DC-NDLもこの方法に基づき、語彙定義とアプリケーションプロファイル(記述セットプロファイル)の定義を分離しています。
解説:DC-NDLの変遷
DC-NDLの祖は、2001年3月に策定した国立国会図書館メタデータ記述要素(NDLメタデータ)に遡ります。その後、2007年5月に国立国会図書館ダブリンコアメタデータ記述要素(DC-NDL2007年版)、2010年6月に国立国会図書館ダブリンコアメタデータ記述(DC-NDL2010年6月版)を策定し、国立国会図書館ダブリンコアメタデータ記述(DC-NDL2011年12月版)で一部改訂を行いました。現在の最新版である国立国会図書館ダブリンコアメタデータ記述(DC-NDL2020年12月版)は、DC-NDL2011年12月版を一部改訂したものです。これまでのDC-NDLの変遷は、以下をご参照ください。
| 文書名 | 策定年月 | 概要 |
|---|---|---|
| 国立国会図書館メタデータ記述要素 (NDLメタデータ) |
2001年 3月 |
|
| 国立国会図書館ダブリンコアメタデータ記述要素(DC-NDL2007年版) | 2007年5月 |
|
| 国立国会図書館ダブリンコアメタデータ記述(DC-NDL2010年6月版) | 2010年6月 |
|
| 国立国会図書館ダブリンコアメタデータ記述(DC-NDL2011年12月版) | 2011年12月 |
|
| 国立国会図書館ダブリンコアメタデータ記述(DC-NDL2020年12月版) | 2020年12月 |
|
解説:セマンティクスとシンタックスの分離
2.1. アプリケーションプロファイルへの対応で説明するとおり、語彙の意味(セマンティクス)を定義する基本記述要素集合*と語彙の記述方法・記述形式(シンタックス)を定義するアプリケーションプロファイル*は、別に分けることが推奨されており、DC-NDLもこれに従っています。セマンティクスとシンタックスの関係は、図で表すと、以下のようになります。
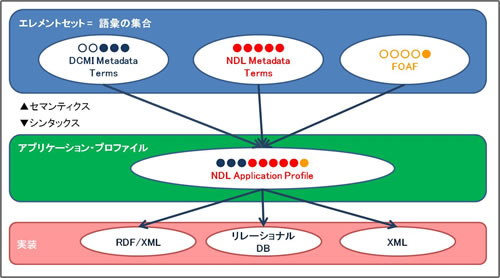
図9:セマンティクスとシンタックスの関係図(1)
アプリケーションプロファイルは、各種の基本記述要素集合メタデータ記述に使用する語彙を選択し、選択した語彙の使用法を規定します。例えば、DC-NDLのアプリケーションプロファイルでは、DCMIメタデータ語彙*からタイトル(dcterms:title)や作成者(dcterms:creator)、NDL Metadata Termsから版表示(dcndl:edition)や価格(dcndl:price)をそれぞれ選択しています。
下図に示すとおり、他のシステムや機関が基本記述要素集合から必要な語彙を選択して、アプリケーションプロファイルを作成することで、メタデータの提供を行う機関間で語彙の意味共有が容易になり、メタデータの連携・交換がしやすくなります。セマンティクスとシンタックスの分離は、メタデータの相互運用性を向上させるための基盤をもたらしていると言えます。
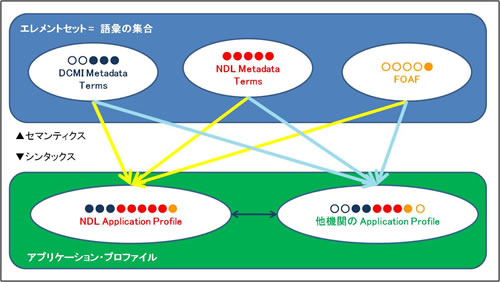
図10:セマンティクスとシンタックスの関係図(2)
解説:Transcriptionと○○ Transcriptionの使い分け
○○ Transcriptionには、タイトルの読み(Title Transcription)、作成者の読み(Creator Transcription)、主題の読み(Subject Transcription)といった語彙があります。
例えば、TranscriptionとTitle Transcriptionは、以下のとおりの使い分けを行っています。
- Transcription → RDF*形式で記述できる場合に使用。構造化により、値と読みをセットで表現することができます。
- Title Transcription → RDF形式で記述できない場合に使用。値と読みの対応関係はデータ上、表現されません。
(例1)
<dc:title>
<rdf:Description>
<rdf:value>国立国会図書館資料デジタル化の手引</rdf:value>
<dcndl:transcription>コクリツ コッカイ トショカン シリョウ デジタルカ ノ テビキ</dcndl:transcription>
</rdf:Description>
</dc:title>
(例2)
<dcterms:title>国立国会図書館資料デジタル化の手引</dcterms:title>
<dcndl:titleTranscription>コクリツ コッカイ トショカン シリョウ デジタルカ ノ テビキ</dcndl:titleTranscription>
解説:構造化表現の必要性
RDF*の構造化表現が有用な例として、国立国会図書館サーチで「図書館・図書館学の発展 : 21世紀初頭の図書館」の書誌詳細画面にアクセスしてみましょう。
このメタデータの「内容細目」という項目に、各著作のタイトルと責任表示が複数記録されています。

図11:「図書館・図書館学の発展 : 21世紀初頭の図書館」の書誌詳細画面(一部)
RDF形式では、以下のように、dcndl:partInformationの配下で、内容細目の各著作のタイトルと責任表示をセットで表現できます。
<dcndl:partInformation>
<rdf:Description>
<dcterms:title>総論 図書館の法と政策に関する動き</dcterms:title>
<dc:creator>山本順一 著</dc:creator>
</rdf:Description>
</dcndl:partInformation>
<dcndl:partInformation>
<rdf:Description>
<dcterms:title>「図書館の自由」をめぐって</dcterms:title>
<dc:creator>山家篤夫 著</dc:creator>
</rdf:Description>
</dcndl:partInformation>
<dcndl:partInformation>
<rdf:Description>
<dcterms:title>図書館像をめぐる論争</dcterms:title>
<dc:creator>嶋田学 著</dc:creator>
</rdf:Description>
</dcndl:partInformation>
<dcndl:partInformation>
<rdf:Description>
<dcterms:title>デジタル環境下の図書館</dcterms:title>
<dc:creator>高鍬裕樹 著</dc:creator>
</rdf:Description>
</dcndl:partInformation>
<dcndl:partInformation>
<rdf:Description>
<dcterms:title>館種別状況 公共図書館</dcterms:title>
<dc:creator>新出 著</dc:creator>
</rdf:Description>
</dcndl:partInformation>
一方、構造化できない形式の場合には、内容細目の各著作のタイトルと責任表示をセットで表現することはできず、それぞれの対応関係を判断することができません。
<dcndl:partTitle>総論 図書館の法と政策に関する動き</dcndl:partTitle>
<dcndl:partTitle>「図書館の自由」をめぐって</dcndl:partTitle>
<dcndl:partTitle>図書館像をめぐる論争</dcndl:partTitle>
<dcndl:partTitle>デジタル環境下の図書館</dcndl:partTitle>
<dcndl:partTitle>館種別状況 公共図書館</dcndl:partTitle>
<dcndl:partCreator>山本順一 著</dcndl:partCreator>
<dcndl:partCreator>山家篤夫 著</dcndl:partCreator>
<dcndl:partCreator>嶋田学 著</dcndl:partCreator>
<dcndl:partCreator>高鍬裕樹 著</dcndl:partCreator>
<dcndl:partCreator>新出 著</dcndl:partCreator>
構造化できない形式のメタデータでは、内容細目のタイトルと著者の組合せは、n×m通り存在することになります。構造化は、元データの意味構造(関係性)をそのまま表現できるようにすることで、コンピュータが意味構造を理解し、処理することを可能にしていると言えます。
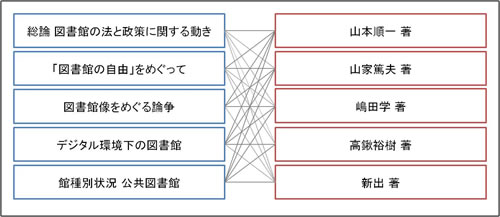
図12:内容細目のタイトルと著者の組合せイメージ
用語集
当ページに出現する各用語の説明については、【参考】メタデータ関連用語集をご参照ください。
この解説は、2012年4月に開催された情報組織化研究グループ月例研究会報告における「国立国会図書館ダブリンコアメタデータ記述(DC-NDL)解読講座」(国立国会図書館電子情報部 柴田洋子)の発表内容を再構成・編集したものです。当日の発表の概要、配布資料は以下をご覧ください。
参考文献
- (1)杉本重雄, 「Dublin Coreについて 第1回 ―概要―」, 情報管理, 45(4), p. 241, 2002,
http://dx.doi.org/10.1241/johokanri.45.241, (参照2012-10-17). - (2)杉本重雄, 「Dublin Coreについて 第2回 ―より深い理解のために―」, 情報管理, 45(5), p. 321-335, 2002,
http://dx.doi.org/10.1241/johokanri.45.321, (参照2012-10-17). - (3)杉本重雄, 「Dublin Coreの現在 (『ディジタル図書館』ワークショップ第36回 発表論文)」, ディジタル図書館, 36, p. 32-45, 2009,
http://hdl.handle.net/2241/103603, (参照2012-10-17). - (4)杉本重雄, 「メタデータについて : Dublin Coreを中心として」, 情報知識学会誌, 10(3), p. 53-58, 2000,
http://ci.nii.ac.jp/naid/110003320657, (参照2012-10-17). - (5)谷口祥一, メタデータの「現在」 : 情報組織化の新たな展開. 勉誠出版, 2010.
DC-NDL等のメタデータ標準に関する問い合わせ先
国立国会図書館 電子情報部
電子情報流通課 標準化推進係
メールアドレス:standardization![]()