
リンクトオープンデータ(LOD)の活用
国立国会図書館は、保有するメタデータを様々なシステムやアプリケーションで活用することができるように、リンクトオープンデータ(Linked Open Data: LOD)として提供しています。このページでは、国立国会図書館が提供するLODの活用事例や活用可能性について紹介します。各データの内容については「リンクトオープンデータ(Linked Open Data: LOD)」をご覧ください。
1. 国立国会図書館が提供するLODの活用事例
国立国会図書館のLODは、様々なシステムやアプリケーションで活用されていますが、その代表的なものをご紹介します。なお、国立国会図書館サーチのAPIの活用事例については、「国立国会図書館サーチリンク集」をご覧ください。
| サービス名 | 作成者 | 概要 |
|---|---|---|
| カーリル | 株式会社カーリル | 全国7,300以上の図書館からリアルタイムの貸出状況を検索できるサービスです。 「国立国会図書館サーチ」の書誌データを利用しています。 |
| GeoNames.jpと国立国会図書館典拠データのリンクセット | インディゴ(株)ラボチーム | GeoNames.jpと「国立国会図書館典拠データ検索・提供サービス:Web NDL Authorities」に含まれる同一地名のURIをつないだリンクセットです。 |
| 京都が出てくる本のデータ | ししょまろはん | 京都が出てくる小説やマンガ、ライトノベル等の情報のLODです。作品の書誌データに加え、作品に出てくる京都のスポットの名称や緯度・経度情報、京都度(京都が出てくる割合)などが含まれています。「Web NDL Authorities」の典拠データを利用しています。 (参考:ししょまろはんのLOD(Linked Open Data)に関する取組み―Web NDL Authoritiesの利活用事例紹介) |
2. 国立国会図書館が提供するLODの活用可能性
国立国会図書館が提供するLODを他のデータと組み合わせて使うことで、例えば次のようなサービスが考えられます。
おすすめ情報をリアルタイムに提供するアプリの例
図1は、アプリのイメージです。このアプリは、使う人の好みを推測し、その対象や範囲を選択肢として提供するものです。何か面白いことや興味を惹かれるものがないか探したいときに、インターネット上の膨大な情報から探すための足掛かりを提供します。このアプリを実現するためのデータの一つとして、国立国会図書館が提供するLODを活用することができます。その一例を見てみましょう。
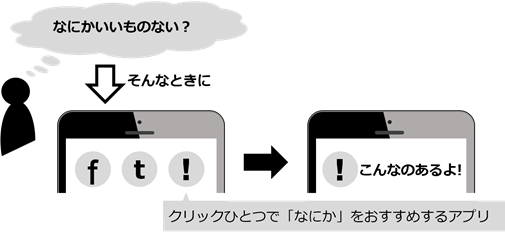
図1 おすすめ情報をリアルタイムに提供するアプリのイメージ
まず、使う人に関連する情報を抽出します。図2の例では、現在地(位置情報)、現在時刻(時間情報)、利用者の日頃の関心情報を対象としています。関心情報には、読書アプリでメモやマーカーを付けた言葉、ブログ記事やソーシャルネットワーキングサービス(SNS)に投稿した言葉やコメントなどの単語が含まれています。
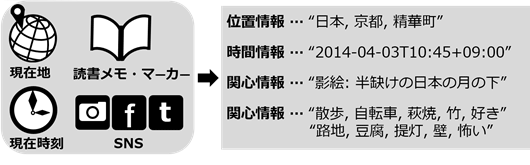
図2 使う人に関連する情報を抽出した例
図3は、使う人の好みにあった情報を選んだ例です。図2で抽出した関心情報を、感情ごとにカテゴリ分けした辞書と照合して、「好き」「お気に入り」などの快感情と組み合わせて使われている単語を選びます。

図3 使う人の好みにあった情報を選んだ例
図4は、使う人の好みの対象や範囲を広げた例です。使う人に多様な情報を提供するため、図3で選んだ単語をDBpedia Japaneseの同じ単語とリンクさせ、関連する人名、作品名、地名、分野名などを抽出します。
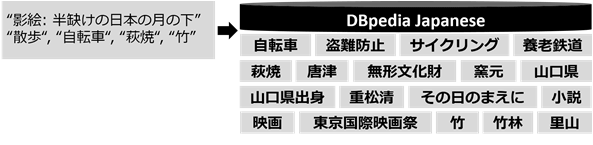
図4 使う人の好みの対象や範囲を広げた例
図5と図6は、広げた情報を整理した例です。図5では、図4で抽出した単語をWeb NDL Authoritiesの典拠データとリンクさせることで個人名(著者)と地名のデータに分けています。地名のデータは、総務省の全国地方公共団体コードを用いれば、都道府県や市町村のレベルに分けて整理できます(「京都府」と「精華町」、「山口県」と「山口市」など)。図6は、図5で整理した個人名(著者)のデータを国立国会図書館サーチの書誌データとリンクさせることで、著者と作品名のデータを組み合わせています。

図5 広げた情報を整理した例1
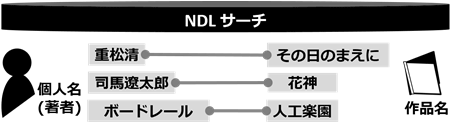
図6 広げた情報を整理した例2
図7は、図5と図6で整理したデータを用いて、アプリ上で選択肢とするデータを選んだ例です。図5で整理した地名のデータをレストランの所在地データや食品の産地データとリンクさせ、地名が一致するデータを選んでいます。
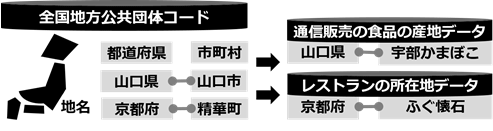
図7 選択肢とするデータを選んだ例
図8は、これまで抽出・整理したデータをアプリの選択肢とするために分類した例です。図6で整理した著者と作品名のデータセットは、「読む」に分類しています。また、図7で選んだ食品やレストランのデータは、「食べる」に分類しています。
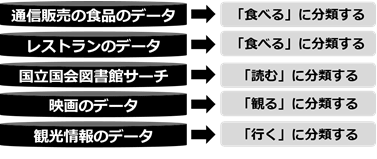
図8 アプリの選択肢として分類した例
このようにして、図9のアプリ完成例のように、使う人の好みにあったおすすめ情報をリアルタイムに提供するサービスを実現できる可能性があります。
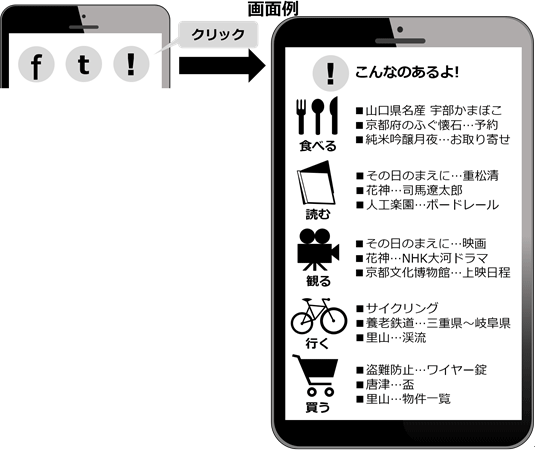
図9 おすすめ情報をリアルタイムに提供するアプリの完成例
3. 参考文献
- (1)NDL書誌情報ニュースレター「典拠の国際流通―バーチャル国際典拠ファイル(VIAF)への参加」連載(1)2012年4号(通号23号)、連載(2)2013年1号(通号24号)、連載(3)2013年2号(通号25号)、「コラム:書誌データ利活用(3) ―Web NDL Authorities(国立国会図書館典拠データ検索・提供サービス)」2014年1号(通号28号)
リンクトオープンデータ(LOD)の活用に関する問い合わせ先
国立国会図書館 電子情報部
電子情報流通課 標準化推進係
メールアドレス:standardization![]()